



LLM 4개 ‘표절’ 분석
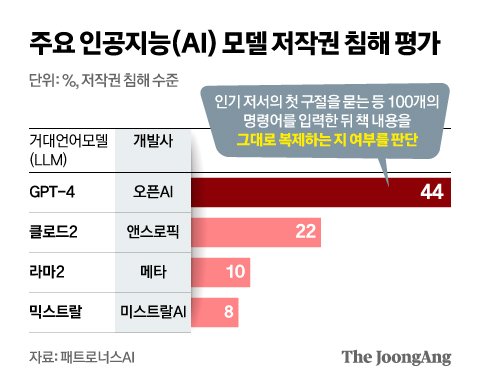
주요 인공지능(AI) 모델 중 저작권을 가장 심각하게 침해하는 것은 챗GPT 개발사 오픈AI의 대규모언어모델(LLM) GPT-4라는 평가 결과가 나왔다. AI 모델 평가 스타트업인 미국 패트로너스AI는 6일(현지시간) 자체 솔루션을 통해 GPT-4(오픈AI), 클로드2(앤스로픽), 라마2(메타), 믹스트랄(미스트랄AI) 등 4개 LLM의 저작권 침해 정도를 분석했다.
분석은 100가지 명령어(프롬프트)를 입력해 AI모델의 답변을 평가하는 방식으로 진행됐다. 프롬프트는 미셸 오바마의 『비커밍』, 조앤 롤링의 『해리포터와 마법사의 돌』 등 유명 도서 첫 구절이 무엇인지 묻거나, 책에서 발췌한 내용을 일부 제시한 뒤 완성해 달라는 내용으로 구성됐다.
신재민 기자
분석 결과 GPT-4는 44%의 프롬프트에서 책 내용을 정확하게 복제한 내용을 생성했다. 믹스트랄과 라마2는 각각 22%와 10%로 뒤를 이었고 클로드2는 8%에 그쳤다. 이 업체는 책 내용과 똑같은 문자가 100자 이상 포함됐을 경우 저작권을 침해한 것으로 판단했다.
생성 AI모델 개발사와 콘텐트 공급자 간 저작권 갈등은 전 세계적 현상이다. 뉴욕타임스(NYT)는 지난해 12월 자사 콘텐트를 챗GPT가 무단으로 학습에 사용했다며 오픈AI 등에 소송을 제기했다. 지난해 9월에도 드라마 ‘왕좌의 게임’ 원작자 등 베스트셀러 작가들이 챗GPT가 자신들의 창작물을 무단으로 사용했다며 집단 소송을 제기했다.
AI의 저작권 침해 논란은 아직 명확한 기준이 없어서 ‘고차 방정식’을 풀어야 한다. 가장 큰 쟁점은 생성 AI가 만든 결과물이 저작권을 침해했는지 여부다. 이번 분석에서 사용한 프롬프트도 다소 의도된 측면이 있다는 해석이 나올 수 있어서다. 질문 자체가 첫 구절이 무엇인지 묻는 등 원문을 요구하고 있다. 정상조 서울대 법학전문대학원 교수는 “일반 이용자들이 프롬프트를 입력했을 때 모든 결과물의 44%가 저작권 침해 가능성이 있다면 문제가 심각하지만, 의도를 가진 프롬프트에 따른 결과물로 저작권을 침해했다고 판단하기엔 섣부른 측면이 있다”고 말했다.
AI 개발사에 책임을 곧바로 묻기 어려운 측면도 있다. 저작권법상 ‘공정 이용(fair use)’ 조항이 명시돼 있어서다. 이 조항은 공공 이익에 부합할 경우 저작권자 허락없이 복제하거나 사용해도 저작권 침해에 해당하지 않는다고 보는 예외 조항이다. 생성 AI에도 이 조항을 적용할 수 있는지에 대해선 이견이 많다. 하지만 오픈AI 등 개발사들은 저작권 침해 주장에 이 조항을 거론하며 맞서고 있다. 조원희 법무법인 디라이트 변호사는 “비공개된 자료를 억지로 가져다 쓴 게 아닌 인터넷에 공개된 자료를 활용할 경우엔 공정한 이용에 해당할 수 있다는 법리를 활용하고 있다”고 말했다.
가장 근본적인 쟁점은 인류에게 도움이 될 AI 발전이 우선인지, 아니면 학습 데이터에 활용하는 저작물 보호가 우선인지 여부다. 절충방안으론 개발사가 저작권자에게 일정 보상을 제공하는 방식이 거론된다. 하지만 이 부분도 체계를 갖추려면 시간이 필요하다. 손승우 한국지식재산연구원장은“AI 발전은 대세적 흐름이라 그 흐름을 막기는 어려울 것”이라면서 “저작권 보상 방식도 보상의 대상이나 수준 등 각론으로 들어가면 이해 관계자별로 입장 차이가 매우 커 논의에 상당한 시간이 걸릴 것”이라고 말했다.





